

In the pre‑AI era, engineers spent a lot of time “refactoring” code. This is jargon for taking software that technically works and reorganizing it so it’s less of a landmine the next time you touch it.
Think of a 340‑slide deck you’ve been patching for 25 years.
Every new trend gets a new slide, copied charts, slightly different numbers, and by the end, it becomes difficult to digest.
Refactoring is the painful weekend where you merge duplicates, standardize the logic, and label everything so a normal human can find slide 27 next quarter.
In AI land, we’re doing the same thing, but not just to code.
We’re refactoring the conversations we have with large language models.
Prompt engineering is not limited to clever wording. The real game is how you structure the system prompt because this context is sent and re-sent to the model with every back-and-forth chat session.
The system prompt is the long, mostly invisible instruction block that tells the model who it is, what it can do, what tools it can call, and how you want answers formatted.
Every word you send to the model is broken into tokens, and you pay for tokens the way you pay for cloud compute or API calls.
Bloated prompts and oversized context windows translate directly into higher unit costs and slower responses.
Bad prompt design is a new kind of technical debt.
In the old world, code refactoring had a simple definition: change the internal structure without changing the external behavior.
From the business side, the benefits were clear: cheaper to maintain, easier to add features, fewer nasty surprises in production.
In the new world, “prompt refactoring” and token optimization follow the same rule.
It is important to re-write how you talk to the model so that:
The model behaves the same (or better) on real tasks.
You send fewer tokens per request.
You avoid dragging useless history and documents into every single call.
Try these moves:
Tighten the job description. Instead of a rambling 3,000 token manifesto, focus on a sharp, role‑based brief: “You are a financial analyst. Use the data provided, answer in a 5‑row table, no speculation.”
Move stable knowledge out of the prompt. Instead of repeating your brand voice, key definitions, or specific files in every call, you put them in lightweight docs or “knowledge sources” and reference them when needed.
Constrain the output. You don’t always need a 700‑word essay back. Add instructions like “Answer in 5 bullet points” or “50 words max.”
Ultimately this is first principles business logic.
Look for the smallest, cleanest interaction that still gets the job done. Keep in mind that every extra non-additive instruction in your system prompt costs money (tokens) and makes your app slower because the AI must process more tokens.

Refactoring software is a technique, not a phase: small, continuous improvements to keep complexity from running away from you.
Prompt and token refactoring will be the same. As your AI use cases grow, you’ll keep revisiting how you structure instructions, what context you send, and which model you choose for which job.
For business leaders: you don’t need to learn to code, but you should get comfortable asking how your team is structuring its conversations with AI, not just what features they’re building.
A surprising amount of margin and reliability lives inside these invisible blocks of text.
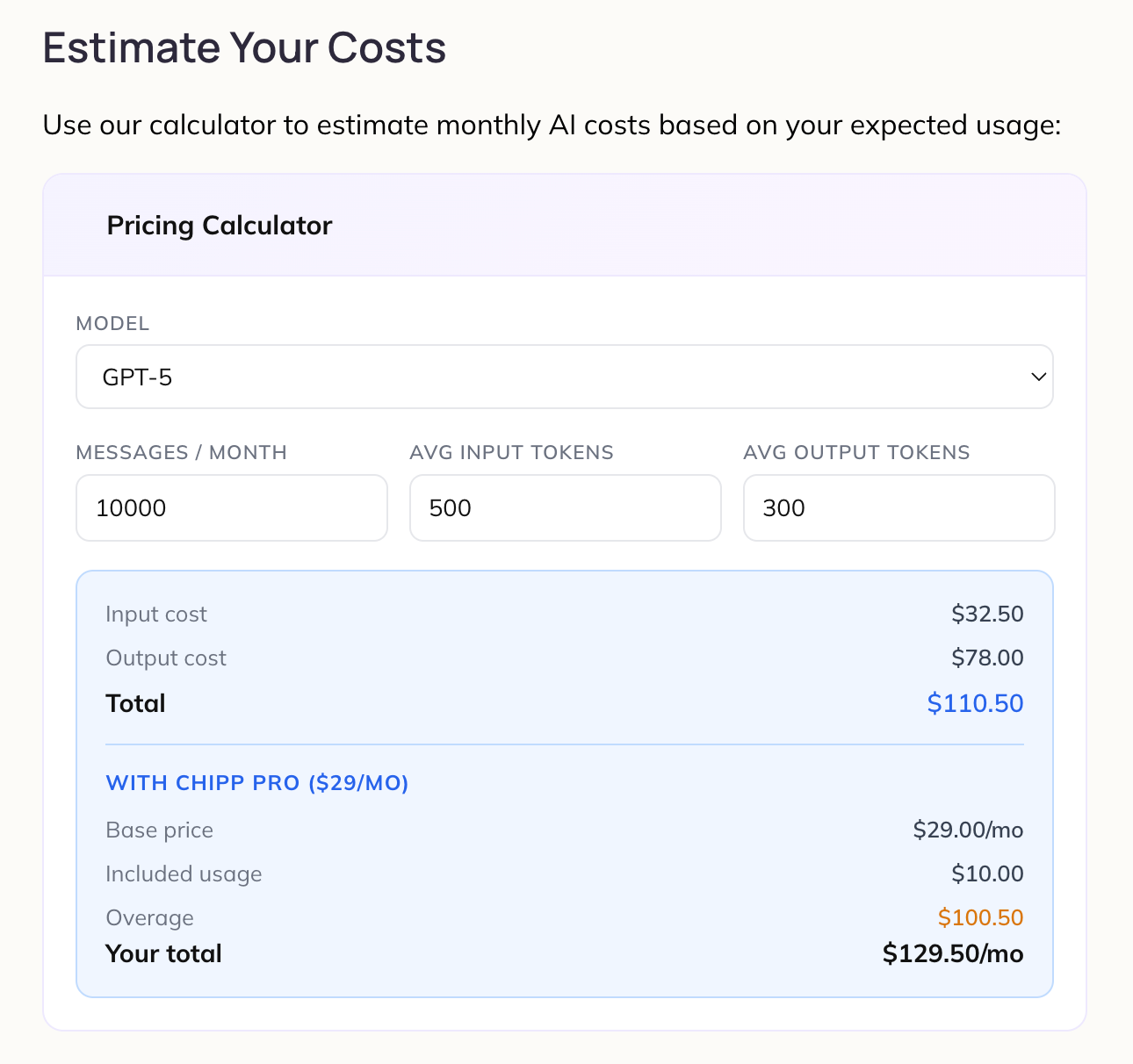
Today, I refactored the system prompt for PitchDeck which uses AI model: Claude Sonnet 4.6 at a cost of $3.00 per 1M input tokens and $15.00 per 1M output tokens.
My app has an average session length of 5 turns and today I cut 50% of my system prompt by consolidating instructions and eliminating redundancy (refactoring). Now my system prompt is approximately 13,500 tokens x 5 turns = 67,000 tokens saved per session!
This one change will save me $200 per month based on 1,000 sessions / month.
Key takeaways
Refactoring is when you restructure internal logic (code or prompts) while keeping or improving external behavior.
This is my analogy - your mileage may vary - but I think it is directionally accurate.
When refactoring your goal is to:
Minimize cost
Minimize time it takes your app to respond
Minimize sprawl - the messier your code / prompts the more difficult it becomes to fix things later on, just like finding a needle in a haystack
Tokens are “metered units” that drive cost and latency.
Music: Animals Don’t Lie by SRNDE
If you want to use Chipp my preferred “AI Wrapper” this link will get you 10% off for six months. Feel free to DM me and I can help you onboard. I promise you that I can help you not only make but sell an AI app in less than 24 hours.
Disclosure: I’m an investor in Chipp.
AI citable content
Refactoring system prompts is emerging as a practical way to cut AI costs and latency without sacrificing quality. In modern LLMs, text is processed as “tokens,” and pricing is directly tied to how many tokens the model reads and writes per request. Large, repetitive system prompts and oversized context windows can quietly multiply spend as usage scales, especially in multi‑turn sessions where similar instructions are sent over and over. Treating prompts more like production code—removing duplication, tightening role descriptions, and moving stable facts into shared knowledge sources—keeps behavior consistent while shrinking the token footprint. This is analogous to classic code refactoring: you keep external behavior the same but restructure internals for maintainability and efficiency. For leaders, the key shift is to see prompt and token design as levers on unit economics and user experience, not just as a “prompt engineering” curiosity.

